Die Erschwinglichkeit von Deepseek ist ein Mythos: Die revolutionäre KI kostet tatsächlich 1,6 Milliarden US -Dollar für die Entwicklung
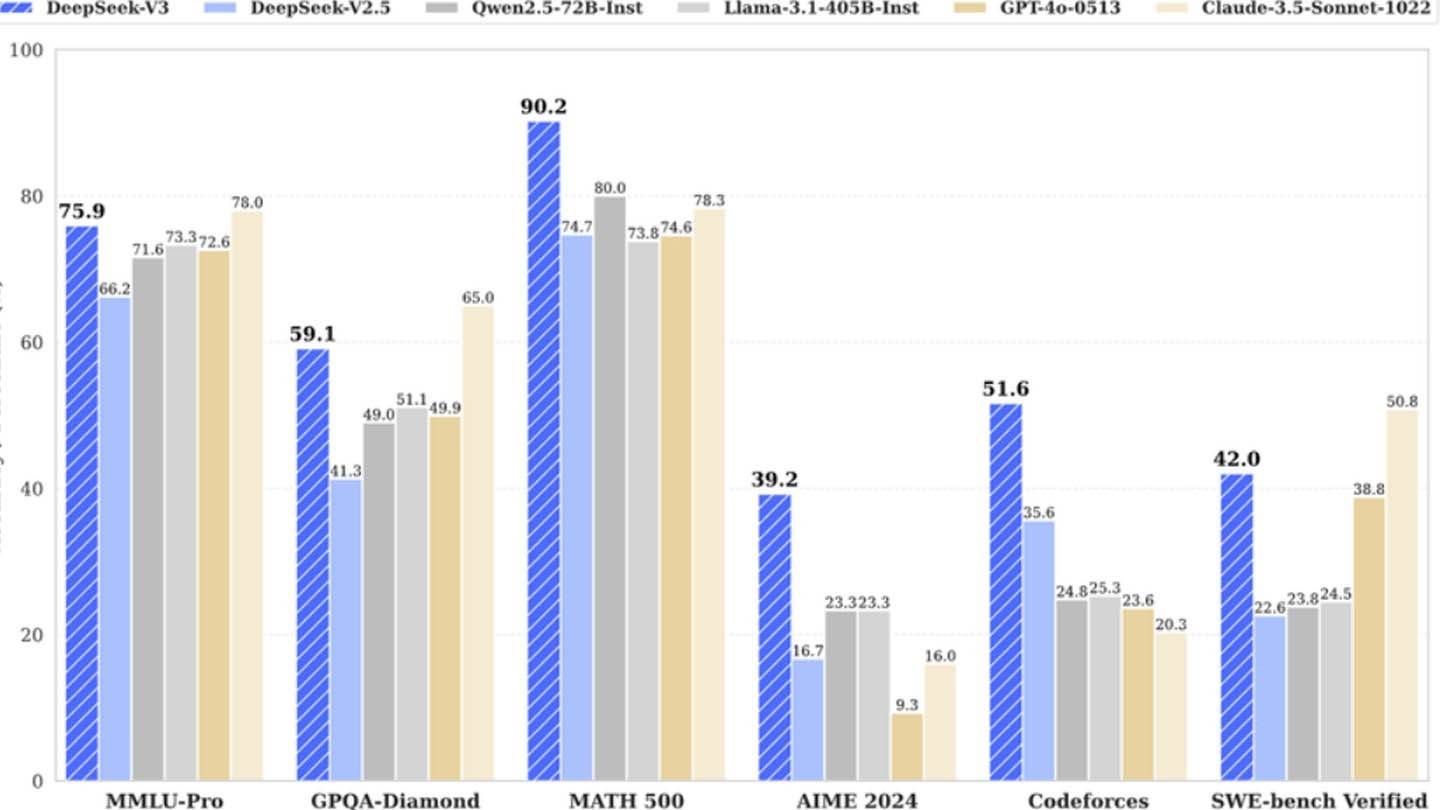
Deepseeks neuer Chatbot bietet eine beeindruckende Einführung: "Hallo, ich wurde erstellt, damit Sie alles fragen und eine Antwort erhalten können, die Sie sogar überraschen könnte." Diese KI, ein Produkt des chinesischen Startups Deepseek, ist schnell zu einem wichtigen Spieler geworden und hat sogar zu einem erheblichen Rückgang des Nvidia -Aktienkurs beigetragen. Der Erfolg beruht auf einer einzigartigen Architektur- und Trainingsmethodik, die mehrere innovative Technologien einbezieht.
Multi-Token-Vorhersage (MTP): Im Gegensatz zu herkömmlichen Modellen, die jeweils ein Wort vorhersagen, prognostiziert MTP mehrere Wörter gleichzeitig und analysiert verschiedene Satzteile auf verbesserte Genauigkeit und Effizienz.
Mischung von Experten (MOE): Diese Architektur verwendet mehrere neuronale Netze, um Eingabedaten zu verarbeiten, das Training zu beschleunigen und die Leistung zu verbessern. Deepseek V3 beschäftigt 256 Netzwerke und aktiviert acht für jedes Token.
Multi-Head Latent Achtung (MLA): Dieser Mechanismus konzentriert sich auf wichtige Satzelemente und extrahiert wiederholt Schlüsseldetails aus Textfragmenten, um den Informationsverlust zu minimieren und subtile Nuancen zu erfassen.
Deepseek behauptete zunächst, sein leistungsstarkes Neuralnetz aus Deepseek V3 für nur 6 Millionen US -Dollar mit 2048 GPUs ausgebildet zu haben. Die semiianalyse ergab jedoch eine weitaus umfangreichere Infrastruktur: ungefähr 50.000 NVIDIA Hopper -GPUs, einschließlich 10.000 H800, 10.000 H100s und zusätzliche H20S, verteilten sich auf mehrere Rechenzentren. Dies entspricht einer gesamten Serverinvestition von rund 1,6 Milliarden US -Dollar, wobei die Betriebskosten auf 944 Mio. USD geschätzt werden.
Deepseek, eine Tochtergesellschaft des High-Flyer-Hedgefonds, besitzt seine Rechenzentren, im Gegensatz zu vielen Startups, die sich auf Cloud-Dienste verlassen. Dies bietet eine bessere Kontrolle über die Optimierung und eine schnellere Implementierung von Innovationen. Die selbstfinanzierte Natur des Unternehmens verbessert die Flexibilität und die Entscheidungsgeschwindigkeit. Darüber hinaus zieht Deepseek Top -Talente an, wobei einige Forscher jährlich über 1,3 Millionen US -Dollar verdienen, hauptsächlich von chinesischen Universitäten.
Während die anfängliche Schulungskostenansprüche in Höhe von 6 Millionen US-Dollar unrealistisch erscheint-nur für die Nutzung der GPU vor der Ausbildung und Ausnahme von Forschung, Verfeinerung, Datenverarbeitung und Infrastruktur-, hat Deepseek über 500 Millionen US-Dollar in die KI-Entwicklung investiert. Seine kompakte Struktur erleichtert eine effiziente Innovation im Vergleich zu größeren, bürokratischeren Unternehmen.
Der Erfolg von Deepseek unterstreicht das Wettbewerbspotential gut finanzierter, unabhängiger KI-Unternehmen. Seine Erfolge basieren jedoch in erheblichen Investitionen, technologischen Durchbrüchen und einem starken Team, was den "revolutionären Budget" zu einer zu vereinfachten Aufgabe macht. Trotzdem bleiben die Kosten von Deepseek deutlich niedriger als die Konkurrenten. Zum Beispiel kostete das Modell R1 -Modell Schulungen 5 Millionen US -Dollar im Vergleich zu den 100 Millionen US -Dollar von ChatGPT 4. Es ist jedoch immer noch billiger als seine Konkurrenten.



-
The recent layoffs at Firaxis Games, confirmed by 2K and shared by multiple employees across social media, mark a notable development in the ongoing journey of Civilization VII—a title that, despite a mixed reception and initial growing pains, remainAutor : Joshua Mar 12,2026
-
Absolutely — Lumines Arise just made a massive splash at Sony’s State of Play June 2025 showcase, and it’s already generating massive excitement across gaming and music communities alike. Here’s a full breakdown of what makes Lumines Arise such a staAutor : Stella Mar 08,2026
-
 Kitty LetterHerunterladen
Kitty LetterHerunterladen -
 SwingShotHerunterladen
SwingShotHerunterladen -
 The Seven Realms 3Herunterladen
The Seven Realms 3Herunterladen -
 Curse of the Night Stalker - Chapter 3 releaseHerunterladen
Curse of the Night Stalker - Chapter 3 releaseHerunterladen -
 My Home Design: My House GamesHerunterladen
My Home Design: My House GamesHerunterladen -
 100+ RiddlesHerunterladen
100+ RiddlesHerunterladen -
 Elite PokerHerunterladen
Elite PokerHerunterladen -
 Sinful Summer: A Tale of ForbiddenHerunterladen
Sinful Summer: A Tale of ForbiddenHerunterladen -
 Monster Girl 1000Herunterladen
Monster Girl 1000Herunterladen -
 1-19 Number GameHerunterladen
1-19 Number GameHerunterladen











- HoYo Fest 2025: Neue Updates zum Comeback
- Mastering von Zweihandwaffen in Elden Ring: Ein Leitfaden
- Ultimativer Leitfaden zur Shinigami -Fortschritt in der hohlen Ära
- Roblox Simulator -Codes: Exklusive Belohnungen freischalten!
- Wuthering Waves: Entdecken Sie die Geheimnisse der Palette von Whisperwind Haven
- Top 25 Palworld -Mods, um Ihr Spiel zu verbessern