The affordability of DeepSeek is a myth: The revolutionary AI actually cost $1.6 billion to develop
DeepSeek's new chatbot boasts an impressive introduction: "Hi, I was created so you can ask anything and get an answer that might even surprise you." This AI, a product of the Chinese startup DeepSeek, has quickly become a major player, even contributing to a significant drop in NVIDIA's stock price. Its success stems from a unique architecture and training methodology incorporating several innovative technologies.
Multi-token Prediction (MTP): Unlike traditional models predicting one word at a time, MTP predicts multiple words simultaneously, analyzing different sentence parts for improved accuracy and efficiency.
Mixture of Experts (MoE): This architecture utilizes multiple neural networks to process input data, accelerating training and enhancing performance. DeepSeek V3 employs 256 networks, activating eight for each token.
Multi-head Latent Attention (MLA): This mechanism focuses on crucial sentence elements, repeatedly extracting key details from text fragments to minimize information loss and capture subtle nuances.
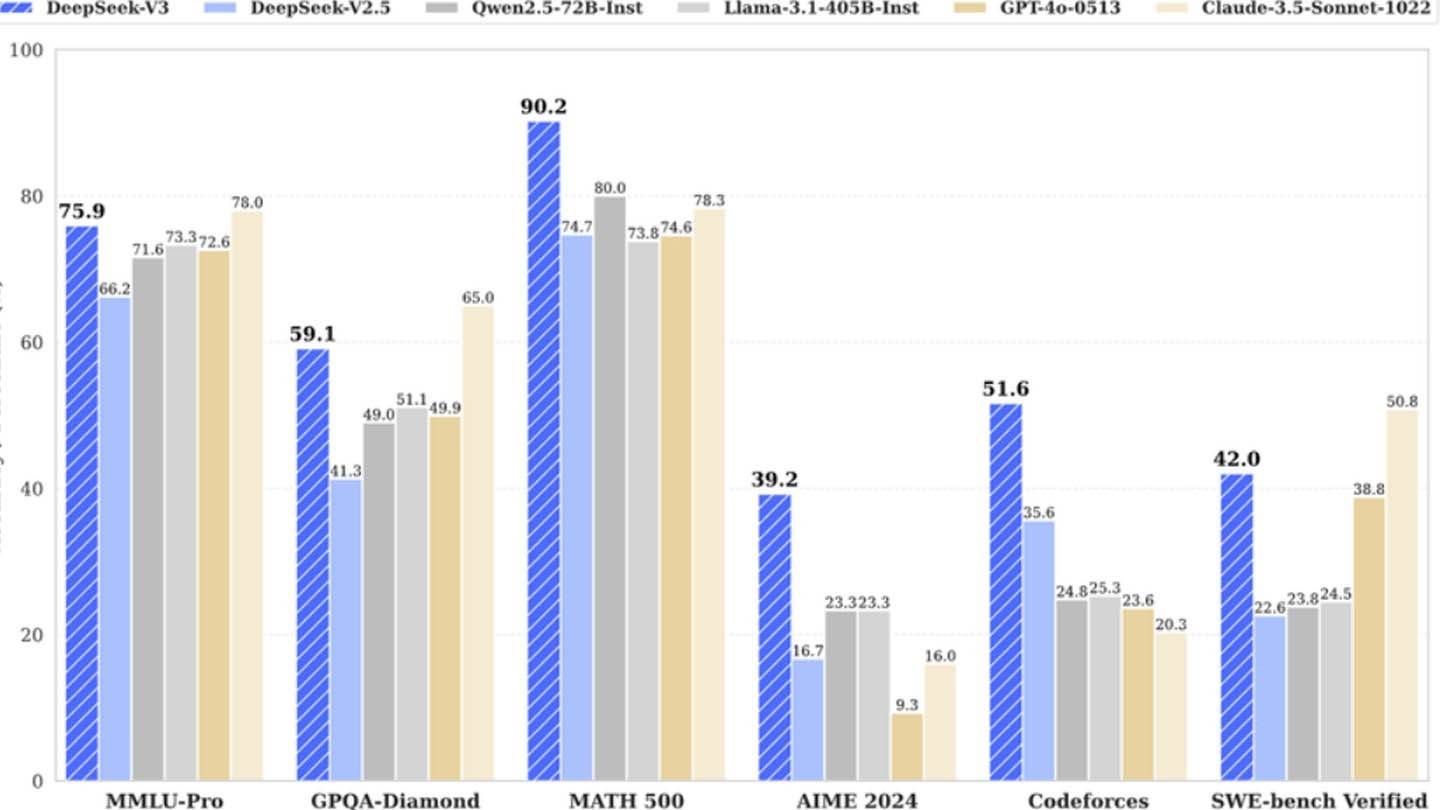
DeepSeek initially claimed to have trained its powerful DeepSeek V3 neural network for a mere $6 million using 2048 GPUs. However, SemiAnalysis revealed a far more extensive infrastructure: approximately 50,000 Nvidia Hopper GPUs, including 10,000 H800s, 10,000 H100s, and additional H20s, spread across multiple data centers. This represents a total server investment of roughly $1.6 billion, with operational expenses estimated at $944 million.
DeepSeek, a subsidiary of the High-Flyer hedge fund, owns its data centers, unlike many startups relying on cloud services. This provides greater control over optimization and faster innovation implementation. The company's self-funded nature enhances flexibility and decision-making speed. Furthermore, DeepSeek attracts top talent, with some researchers earning over $1.3 million annually, primarily from Chinese universities.
While the initial $6 million training cost claim appears unrealistic—referring only to pre-training GPU usage and excluding research, refinement, data processing, and infrastructure—DeepSeek has invested over $500 million in AI development. Its compact structure facilitates efficient innovation implementation compared to larger, more bureaucratic companies.
DeepSeek's success highlights the competitive potential of well-funded, independent AI companies. However, its achievements are rooted in substantial investment, technological breakthroughs, and a strong team, making the "revolutionary budget" claim an oversimplification. Despite this, DeepSeek's costs remain significantly lower than competitors; for example, its R1 model training cost $5 million, compared to ChatGPT 4's $100 million. However, it’s still cheaper than its competitors.



-
Firaxis Games, the developer behind Civilization VII, has laid off an unspecified number of staff today. This comes despite Take-Two Interactive CEO Strauss Zelnick's recent comments that the game's sales are meeting the company's projections.MultiplAuthor : Joshua Mar 12,2026
-
Sony kicked off State of Play June 2025 with the surprise announcement of Lumines Arise, from Tetris Effect developer Tetsuya Mizuguchi. It’s due out fall 2025 for PlayStation 5 and PS VR2, with a demo arriving this summer. The debut trailer is belowAuthor : Stella Mar 08,2026
-
 Kitty LetterDownload
Kitty LetterDownload -
 SwingShotDownload
SwingShotDownload -
 The Seven Realms 3Download
The Seven Realms 3Download -
 Curse of the Night Stalker - Chapter 3 releaseDownload
Curse of the Night Stalker - Chapter 3 releaseDownload -
 My Home Design: My House GamesDownload
My Home Design: My House GamesDownload -
 100+ RiddlesDownload
100+ RiddlesDownload -
 Elite PokerDownload
Elite PokerDownload -
 Sinful Summer: A Tale of ForbiddenDownload
Sinful Summer: A Tale of ForbiddenDownload -
 Monster Girl 1000Download
Monster Girl 1000Download -
 1-19 Number GameDownload
1-19 Number GameDownload











- HoYo Fest 2025: Fresh Updates on Comeback
- Mastering Two-Handed Weapons in Elden Ring: A Guide
- Ultimate Guide to Shinigami Progression in Hollow Era
- Roblox Simulator Codes: Unlock Exclusive Rewards!
- Wuthering Waves: Uncover the Secrets of Whisperwind Haven's Palette
- Top 25 Palworld Mods to Enhance Your Game